18. praktikum
22.04.2026
Juhumetsad
Tänases praktikumis
- Juhumetsad
- Juhumetsade visualiseerimine
- Juhumetsade headuse näitajad
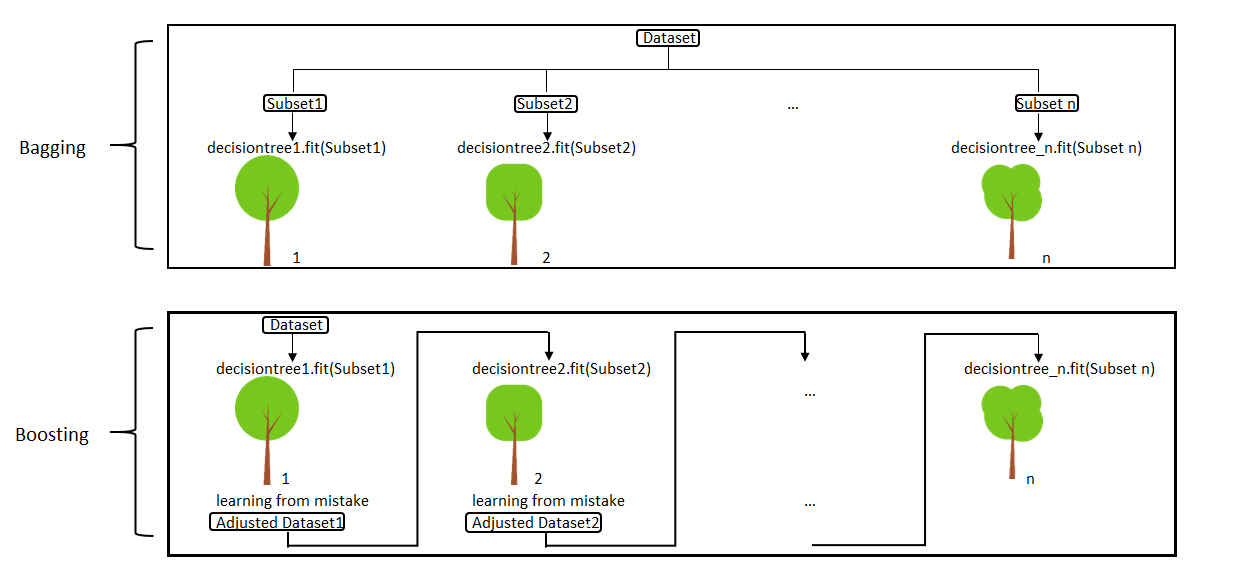
Nagu eelmises praktikumis räägitud, ei pruugi üksikud otsustuspuud olla väga stabiilised. Ehkki need sobivad hästi andmestiku visualiseerimiseks ja nendes esinevate olulisemate seoste tuvastamiseks, ei ole need uue valimi pealt ennustamiseks alati kõige paremad, eriti kui puid ei ole trimmitud. Üks variant otsustuspuude valideerimiseks oli kasutada treening- ja testandmestikke. Teine variant on aga kasutada nn ansamblimeetodeid (ensemble methods), mis kasutavad sageli bootstrap-valikut ning milles lõplik ennustus uuritava tunnuse väärtustele üldistatakse mitmete üksikute puumudelite põhjal. Ka ansamblimeetoditele on palju algoritme, põhilistena eristatakse nn bagging- ja boosting-algoritme.
- Bagging-algoritmides treenitakse
paralleelselt mitut mudelit mitme üksteisest pisut erineva juhusliku
valimi peal ning üldistatakse lõpuks nende mudelite ennustused.
- Boosting-algoritmides treenitakse mudeleid järjekorras ja iga järgmine mudel saab midagi eelmiselt mudelilt õppida. Ühes puus valesti klassifitseeritud vaatlused saavad järgmises puus suurema kaalu.

Bagging ja boosting, https://miro.medium.com/max/2000/1*bUySDOFp1SdzJXWmWJsXRQ.png
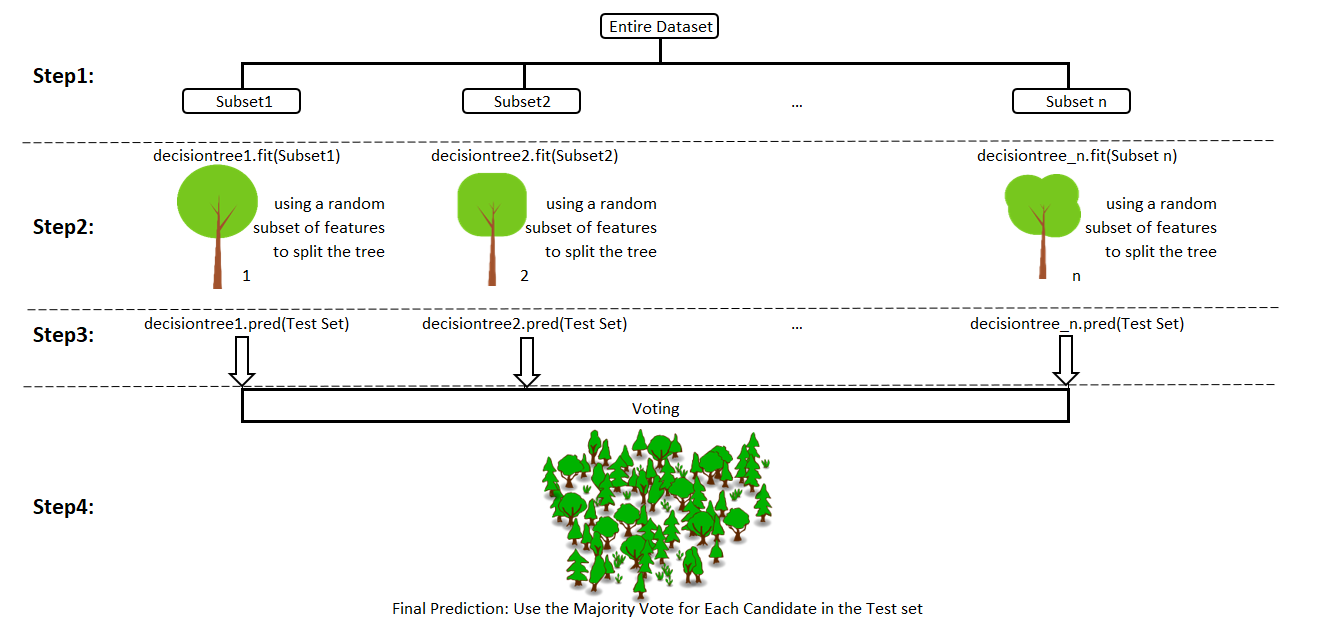
Vaatame lähemalt nn juhumetsa meetodit (random forest), mis on bagging-algoritmi eritüüp.
Juhumets
Juhumets (random forest) on mudel, mis üldistab oma ennustused terve hulga juhuslike puude põhjal. Juhuslikkus tuleneb sealjuures kahest asjaolust:
- andmestikust võetakse mingi hulk juhuslikke
valimeid (kas bootstrap-valimeid ehk sama suuri
valimeid, kus mõni vaatlus/rida võib korduda, mõni aga jääb välja, või
väiksemaid valimeid, milles vaatlused/read korduda ei või) ja igast
valimist kasvatatakse puumudel. Vaatlused, mis valimisse ei satu, on nn
out-of-bag ehk OOB-vaatlused. Iga puu
võib teistest natuke erineda, sest tema aluseks olev valim on veidi
erinev. See on tavaline bagging-algoritmi põhimõte;
- iga juhusliku puu igas sõlmes kaalutakse jagunemiseks
juhuslikku hulka kõigist seletavatest tunnustest. See
loob veelgi erinevamad puud ja annab hääle ka nõrgematele seletavatele
tunnustele (kui mõni väga tugev tunnus, nt meie adessiivi ja
peal-andmestikus tunnus
LM_mobiilsus, esimese sõlme jagunemise valikusse ei satu). See on see, mille poolest juhumets tavalisest bagging’ust erineb.
Lõpliku ennustuse saamiseks puud “hääletavad” iga tegeliku vaatluse ennustatud klassi üle, kui uuritav tunnus on kategoriaalne, või keskmistavad tegeliku vaatluse ennustatud väärtuse, kui uuritav tunnus on arvuline. See tähendab, et iga andmestiku tegelik vaatlus saab mingi ühe ennustatud klassi või keskväärtuse, olenemata sellest, millised need üksikud puumudelid välja näevad.
Out-of-bag vaatlused (iga juhusliku valimi puhul umbes kolmandik andmestikust) toimivad hiljem iga puu n-ö sisseehitatud testandmestikuna.

{kind=link}
{kind=link}
Kasutame endiselt andmestikke ade_peal.csv ja
kandidaadid_2023.csv.
ade_peal <- read.delim("data/ade_peal.csv", encoding = "UTF-8", stringsAsFactors = TRUE)
ade <- ade_peal[ade_peal$cx == "ade",] # ainult alalütleva käände andmed
peal <- ade_peal[ade_peal$cx == "peal",] # ainult peal-kaassõna andmed
set.seed(1) # seeme juhusliku valiku tegemise korratavuseks
juh_id <- sample(x = 1:nrow(peal), # võta ridadelt 1 kuni 1310 juhuslik valim,
size = nrow(ade), # mille suurus oleks sama, mis ade-andmestikul
replace = F) # ära korda ühtegi vaatlust
peal_juhuvalim <- peal[juh_id,] # võta peal-andmestikust ainult juhuslikult valitud read
dat <- droplevels(rbind(ade, peal_juhuvalim)) # liida kaks andmestikku ridupidi uuesti kokkukandidaadid <- read.delim("data/kandidaadid_2023.csv", header = T, sep = "\t", encoding = "UTF-8")
# Teeme juurde tunnused "kasutab_meili", "nime_pikkus" ja "vanus"
kandidaadid$kasutab_meili <- factor(ifelse(grepl("@", kandidaadid$kontakt),
"jah",
"ei"))
kandidaadid$nime_pikkus <- nchar(kandidaadid$nimi)
kandidaadid$vanus <- 2023 -as.numeric(substr(kandidaadid$sünniaeg, 7, 10))randomForest
Kasutame alustuseks funktsiooni randomForest()
samanimelisest paketist. See on kõige põhilisem juhumetsade tegemise
pakett, kuna on kasutajasõbralik, lihtne õppida ja arvutuslikult
võrdlemisi kiire.
Funktsiooni miinuseks on see, et puid vaikimisi ei trimmita ning need võivad ülesobitada. Samuti kalduvad puud eelistama sõlmedes arvulisi tunnuseid ja kategoriaalseid tunnuseid, millel on palju tasemeid. Selles paketis ei tehta niisiis tingimuslikke otsustuspuid, mis kasutavad sõlmedes jagunemiseks valitavate tunnuste määramiseks p-väärtuseid, vaid tavalisi regressiooni- ja klassifitseerimispuid (vt ka 17. praktikumi materjale).
# Kategoriaalne uuritav tunnus
# Kuna juhumetsade mudelid sisaldavad juhuslikkust,
# tuleks tulemuste korratavuse huvides mudeldamisel
# alati määrata ka seeme (seed),
# mis tagab juhuslikkuses teatud fikseeritud seisu.
# Seemneks sobib mis tahes arv.
set.seed(100)
mets_kat_rf <- randomForest(cx ~ TR_liik + tegusõna_klass + LM_mobiilsus + LM_komplekssus + LM_pikkus_log + sõnajärg + murderühm,
data = dat,
importance = TRUE)
# Argumendi `importance` lisamine võimaldab meil hiljem võrrelda tunnuste olulisust
# nii nende täpsuse kui ka klasside puhtuse suurendamise seisukohalt.class(mets_kat_rf) # objektiklass on randomForest
mets_kat_rf$type # metsamudel kasutab klassifitseerimispuid (<- kat. uuritav tunnus)##
## Call:
## randomForest(formula = cx ~ TR_liik + tegusõna_klass + LM_mobiilsus + LM_komplekssus + LM_pikkus_log + sõnajärg + murderühm, data = dat, importance = TRUE)
## Type of random forest: classification
## Number of trees: 500
## No. of variables tried at each split: 2
##
## OOB estimate of error rate: 31.44%
## Confusion matrix:
## ade peal class.error
## ade 478 244 0.3379501
## peal 210 512 0.2908587Vaikimisi tehakse 500 puumudelit ja iga puu igas sõlmes katsetatakse
jagunemiseks 2 juhuslikult valitud tunnust. Enamasti on see arv ruutjuur
seletavate tunnuste arvust, mille randomForest ümardab
allapoole. Antud juhul näiteks on meil mudelis 7 seletavat tunnust,
millest ruutjuur on 2.645751. Kui see allapoole ümardada, saabki
2.
Sellise metsa eksimismäär (OOB estimate of
error rate) on 31.44%, mis tähendab, et
klassifitseerimistäpsus on
100-31.44=68.56%. Täpsust arvutatakse nn
out-of-bag vaatluste põhjal.
- Iga puu tehakse andmestiku põhjal, mis algandmestikust veidi erineb.
Umbes 1/3 algandmestiku vaatlustest jäetakse iga puumudeli aluseks
olevast valimist välja, kusjuures seda 1/3 korvatakse sellega, et
korratakse mingeid vaatlusi ülejäänud 2/3st vaatlustest. Need
1/3 väljajäänud vaatlusi ongi out-of-bag
vaatlused, mida kasutatakse testandmestikuna, et leida iga puu
individuaalne klassifitseerimistäpsus.
- Metsamudeli lõplik klassifitseerimistäpsus üldistatakse seejärel
kõikide puude põhjal: iga algandmestiku vaatluse/rea puhul hääletavad
kõik 500 puud selle üle, mis mingile vaatlusele klassiks määratakse.
Näiteks käsk
mets_kat_rf$votes[1,]näitab, et 70% puudest ennustab, et meie andmestiku 1. real olev vaatlus ei esinda peal-konstruktsiooni esinemisjuhtu, 30% puudest aga ennustab, et esindab küll. Kuna üldsus otsustab, siis saab 1. vaatlus metsamudeli ennustusena peal-konstruktsiooni esinemisele väärtuse “ei”. Nii ennustatakse klassi kõigi 1444 vaatluse puhul algandmestikus. OOB estimate of error rate näitab niisiis nende vaatluste osakaalu, mille puhul metsamudel ennustas valet uuritava tunnuse väärtust. Mida väiksem see protsent on, seda parem.
randomForesti mudel annab väljundis automaatselt ka
õigete ja valede ennustuste risttabeli ehk
confusion matrix’i (ridades tegelikud vaatlused ning tulpades
ennustatud klassid) ning lisaks iga klassi eksimismäära eraldi
(class.error). See on kasulik, kuna vahel võib juhtuda, et
mudel suudab ennustada väga hästi üht, aga mitte teist klassi.
## ade peal class.error
## ade 478 244 0.3379501
## peal 210 512 0.2908587
Saame binaarse kategoriaalse uuritava tunnusega metsamudeli ennustuste põhjal leida jällegi ka C/AUC.
# Leiame metsamudeli ennustatud tõenäosused "peal"-konstruktsioonile
enn_probs <- predict(mets_kat_rf, type = "prob")[,"peal"]
head(enn_probs)## 6 7 8 9 11 13
## 0.30386740 0.06521739 0.01500000 0.94594595 0.80459770 0.56140351## Area under the curve: 0.7378# või
# Teisendame uuritava tunnuse tegelikud väärtused
# samuti tõenäosusteks 0 ("ade") ja 1 ("peal")
teg_probs <- ifelse(dat$cx == "peal", 1, 0)
head(teg_probs)## [1] 0 0 0 0 0 0# C-indeks
library(Hmisc)
somers2(enn_probs, teg_probs)["C"] # enn, teg, mõlemad argumendid tõenäosustena## C
## 0.7378377
Vaatame ka arvulise uuritava tunnusega mudeli väljundit.
# Arvuline uuritav tunnus
set.seed(100)
mets_num_rf <- randomForest(log(hääli_kokku) ~ haridus + sugu + tähtkuju + kasutab_meili + nime_pikkus + vanus,
data = kandidaadid,
subset = haridus != "Põhiharidus",
importance = TRUE)
class(mets_num_rf)## [1] "randomForest.formula" "randomForest"## [1] "regression"##
## Call:
## randomForest(formula = log(hääli_kokku) ~ haridus + sugu + tähtkuju + kasutab_meili + nime_pikkus + vanus, data = kandidaadid, importance = TRUE, subset = haridus != "Põhiharidus")
## Type of random forest: regression
## Number of trees: 500
## No. of variables tried at each split: 2
##
## Mean of squared residuals: 1.902888
## % Var explained: -2.53Arvulise uuritava tunnusega tehakse samuti 500 puud, ent regressioonipuude metsas valitakse igas sõlmes vaatluste jaotamiseks p/3 seletava tunnuse vahel, kus p on seletavate tunnuste arv. Kuna siin on seletavate tunnuste arv mudelis 6, siis proovitakse igas sõlmes jagunemiseks 6/3=2 juhuslikult valitud tunnust.
Regressioonipuud näitavad klassifitseerimistäpsuse asemel
seletatud varieerumise protsenti % Var
explained, mis on põhimõtteliselt sama, mis R2
(tegelikult pseudo-R2). Mean of squared residuals
näitab ruutu võetud jääkide keskmist. Selle absoluutarv sõltub uuritava
arvulise tunnuse skaalast. Siin on arvuline tunnus logaritmitud
häältesaak, mille väärtused võivad üldse varieeruda ainult 0 ja 10.37
vahel (vt range(log(kandidaadid$hääli_kokku))). Seepärast
on väike ka ruutu võetud jääkide keskmine, võrreldes näiteks
reaktsiooniaegade andmestikuga, kus uuritav tunnus on mõõdetud
millisekundites ja ruutu võetud jääkide keskmine võib olla seega
tuhandetes. Sama andmestiku peal tehtud mudelite võrdlusel on aga
väiksem Mean of squared residuals parem.
Tunnuste olulisus
Juhumetsade mudelite üks suuri plusse on see, et need võimaldavad
hinnata mudelisse kaasatud seletavate tunnuste suhtelist olulisust
uuritava tunnuse väärtuste ennustamisel. Seletavate tunnuste olulisust
saab küsida funktsiooniga importance().
Vaatame esmalt jällegi kategoriaalse uuritava tunnusega
mudelit.
Juhul, kui randomForest()-funktsioonis on metsamudeli
tegemisel eelnevalt täpsustatud argument importance = TRUE,
saame lisaks Gini-informatsioonikriteeriumile ka nn
permutatsiooniolulisuse.
## ade peal MeanDecreaseAccuracy MeanDecreaseGini
## TR_liik 10.1410582 7.269014 13.0506235 27.56134
## tegusõna_klass 10.2982033 12.065587 16.2809698 44.24411
## LM_mobiilsus 48.1838446 43.887712 57.3769924 55.21036
## LM_komplekssus 26.1693446 13.412225 30.7603178 21.66096
## LM_pikkus_log 23.0053999 10.150189 25.2397845 45.51921
## sõnajärg 0.6633584 -1.142801 -0.4320659 10.99076
## murderühm 27.7322377 24.403970 34.2147467 50.48720randomForest esitab tunnuste olulisust niisiis kahe
mõõdiku järgi:
MeanDecreaseAccuracynäitab nn permutatsiooniolulisust ehk keskmist kahanemist klassifitseerimistäpsuses, kui konkreetset seletavat tunnust on kõikides puudes permuteeritud. Permuteerimine on protsess, kus OOB-vaatlustel (nendel ridadel, mida ei kasutatud puu konstrueerimiseks) aetakse mingi seletava tunnuse (ntTR_liik) väärtused suvaliselt sassi ning ennustatakse siis uuesti uuritava tunnuse väärtusi. Mida rohkem seletava tunnuse väärtuste sassiajamine suurendab valesti klassifitseerimist, seda suurem on ka tunnuse olulisus, sest seda paremini aitab seletava tunnuse tegelike väärtuste teadmine ennustada uuritava tunnuse väärtust. Kui aga seletaval tunnusel ei ole uuritava tunnuse varieerumisele olulist mõju, siis ei muutu klassifitseerimistäpsus, kui seletava tunnuse väärtusi suvaliselt muuta. KuiMeanDecreaseAccuracyon negatiivne, nagu näiteks meil tunnusesõnajärgpuhul, tähendab see seda, et seletava tunnuse väärtuste suvaline sassiajamine tegelikult isegi parandaks klassifitseerimistäpsust, mis jällegi viitab sellele, et tunnusel ei ole uuritava tunnuse varieerumisele mingit mõju.
MeanDecreaseGinipõhineb lehtede puhtusel ja Gini-informatsioonikriteeriumil, millest rääkisime juba ka otsustuspuude juures. Mida suurem on MeanDecreaseGini, seda enam aitab tunnus kaasa sellele, et puude sõlmedesse ennustatud vaatlused oleksid uuritava tunnuse seisukohalt võimalikult homogeensed (nt sisaldaksid võimalikult palju ainult peal-konstruktsiooni kasutusjuhte või ainult ade-konstruktsiooni kasutusjuhte). Gini-mõõdik kaldub eelistama arvulisi tunnuseid ja selliseid kategoriaalseid tunnuseid, millel on mitu taset. Näiteks onmets_kat_rfmudelis peale tunnuseLM_mobiilsus, mis ilmselt ongi põhiline varieerumise seletaja, selle mõõdiku põhjal järgmiseks kõige olulisemad kategoriaalne tunnusmurderühm, millel on 4 taset, arvuline tunnusLM_pikkus_logjategusõna_klass, millel on tervelt 5 taset. Seega on parem tunnuste olulisuse hindamisel lähtuda permutatsiooniolulisusest, mis on vähem kallutatud.
Kaks esimest tulpa tabelis (ade ja peal)
näitavad, kui palju kasvas mingi tunnuse permuteerimisel vastavalt
ade ja peal vaatluste valesti klassifitseerimine.
Näiteks tunnuse LM_mobiilsus permuteerimine suurendaks
enam-vähem ühepalju nii ade- kui ka
peal-konstruktsioonide valesti klassifitseerimist, tunnused
LM_komplekssus ja LM_pikkus_log on aga
olulisemad ade-konstruktsioonide õigesti
klassifitseerimiseks.
“Toored” permutatsiooniolulisuse skoorid saadakse nii, et iga puu
puhul lahutatakse “puutumata” OOB-vaatluste õigesti klassifitseeritud
juhtude arvust permuteeritud OOB-vaatluste õigesti klassifitseeritud
juhtude arv ning leitakse saadud arvu kõikide puude keskmine.
importance()-funktsioon näitab aga permutatsiooniolulisuse
puhul vaikimisi nn z-skoore
ehk jagab permutatsiooniolulisuse mõõdikud läbi nende standardvigadega.
Vahel on soovitatud kasutada siiski neid “tooreid”, standardiseerimata
(scale = FALSE) olulisusmõõdikuid, kuna z-skoorid
on tundlikumad valimi suuruse ja puude arvu suhtes.
## ade peal MeanDecreaseAccuracy MeanDecreaseGini
## TR_liik 0.0116139290 0.0081223034 0.0098838676 27.56134
## tegusõna_klass 0.0122942829 0.0147071382 0.0134642965 44.24411
## LM_mobiilsus 0.0677285606 0.0723647329 0.0699601955 55.21036
## LM_komplekssus 0.0232493598 0.0101849629 0.0167184240 21.66096
## LM_pikkus_log 0.0318145298 0.0117155374 0.0217415671 45.51921
## sõnajärg 0.0005364291 -0.0009333887 -0.0002239436 10.99076
## murderühm 0.0369555710 0.0327512770 0.0347973662 50.48720Tunnuste olulisust esitatakse tihtipeale ka graafikul. Paketil
randomForest on selleks sisse-ehitatud funktsioon
varImpPlot().


varImpPlot(mets_kat_rf,
main = "Tunnuste permutatsiooniolulisus (standardiseerimata)",
scale = FALSE,
type = 1)
Tunnuste olulisust võib visualiseerida ka nt
ggplot2-ga.
library(ggplot2)
# Tee olulisuse mõõdikutest andmetabel
df <- as.data.frame(importance(mets_kat_rf, scale = FALSE))
head(df)## ade peal MeanDecreaseAccuracy MeanDecreaseGini
## TR_liik 0.0116139290 0.0081223034 0.0098838676 27.56134
## tegusõna_klass 0.0122942829 0.0147071382 0.0134642965 44.24411
## LM_mobiilsus 0.0677285606 0.0723647329 0.0699601955 55.21036
## LM_komplekssus 0.0232493598 0.0101849629 0.0167184240 21.66096
## LM_pikkus_log 0.0318145298 0.0117155374 0.0217415671 45.51921
## sõnajärg 0.0005364291 -0.0009333887 -0.0002239436 10.99076# Joonista ggploti graafik
ggplot(data = df,
aes(y = reorder(rownames(df), MeanDecreaseAccuracy), # y-teljele tabeli df reanimed tunnustega, mis on järjestatud permutatsiooniolulisuse skoori järgi
x = MeanDecreaseAccuracy)) + # x-teljele perm.olulisus
geom_col() + # tulpdiagramm
labs(x = "", y = "",
title = "Tunnuste permutatsiooniolulisus juhumetsa mudelis",
subtitle = "(standardiseerimata)",
caption = "R-i paketiga randomForest (Liaw & Wiener 2002)")
# Teistsugune graafik
ggplot(data = df,
aes(y = reorder(rownames(df), MeanDecreaseAccuracy),
x = MeanDecreaseAccuracy,
fill = MeanDecreaseAccuracy)) + # punktide värv
geom_point(size = 4, shape = 22, show.legend = FALSE) + # punktid
scale_fill_gradient(low = "steelblue4", # mitteoluliste värv
high = "tomato2") + # oluliste värv
labs(x = "",
y = "",
title = "Tunnuste permutatsiooniolulisus juhumetsa mudelis",
subtitle = "(standardiseerimata)",
caption = "R-i paketiga randomForest (Liaw & Wiener 2002)") +
theme_minimal() +
theme(text = element_text(size = 14),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank())
Vaatame ka arvulise uuritava tunnusega metsamudeli tunnuste olulisust.
## %IncMSE IncNodePurity
## haridus 14.488174 41.40613
## sugu 3.836047 38.66479
## tähtkuju 1.753878 170.51391
## kasutab_meili 3.305421 13.50634
## nime_pikkus 8.549109 189.57093
## vanus 5.210100 305.64053- Arvulise uuritava tunnusega metsamudeli puhul näitab esimene tulp
%IncMSEseda, kui palju mingi seletava tunnuse permuteerimine (segiajamine) suurendab nn keskmist ruutviga (mean squared error) ehk OOB-vaatluste põhjal ennustatud väärtuste ja algandmestiku tegelike väärtuste keskmisi erinevusi. Mida suurem selle tulba väärtus on, seda rohkem mõjutab vastav tunnus seda, kui hästi me mudeliga vaatluste uuritava tunnuste väärtusi saame ennustada, ning seda olulisem tunnus on.
- Sellega on osaliselt seotud ka teine tulp,
IncNodePurity, mis näitab, kui palju mingi tunnuse põhjal andmete ositamine puudes suurendab puu sõlmedes uuritava tunnuse väärtuste homogeensust ehk ühetaolisust ning erinevust teistes sõlmedes olevate vaatluste uuritava tunnuse väärtustest. Mida suurem on mingi seletava tunnuseIncNodePurityväärtus, seda erinevamad on selle tunnuse alusel binaarsel ositamisel tekkivad rühmad üksteisest ning seda sarnasemad rühmadesse kuuluvad vaatlused omavahel.IncNodePurity’t peetakse aga suhteliselt kallutatud mõõdikuks, sest seegi eelistab jällegi arvulisi tunnuseid ning mitme tasemega kategoriaalseid tunnuseid, nii et enamasti võiks seletavate tunnuste olulisuse hindamisel eelistada%IncMSE-d.

Puude ja tunnuste arv
Nagu öeldud, teeb R vaikimisi mudeli, kus kasvatatakse 500 puud ja
proovitakse iga puu igas sõlmes nii mitut juhuslikult valitud tunnust,
kui suur on ruutjuur seletavate tunnuste arvust (arvulistel tunnustel
seletavate tunnuste arv / 3). Neid parameetreid saab aga soovi korral
muuta vastavalt argumentidega ntree ja
mtry.
## [1] 500## [1] 2Vaatame, kas mudeli täpsus paraneb, kui proovime sõlmedes erineval hulgal seletavaid tunnuseid.
# Teeme tühja vektori
tapsused <- vector()
# Teeme tsükli, kus
for(i in 2:7){ # iga arvu i kohta 2st 7ni (i = 2, i = 3, i = 4, i = 5, i = 7)
set.seed(100)
# teeme mudeli, kus seletavate tunnuste arv võrdub i-ga
# (nt mudel, kus mtry = 1; mudel, kus mtry = 2 jne,
# kuni mudelini, kus mtry = 7)
mudel <- randomForest(cx ~ TR_liik + tegusõna_klass + LM_mobiilsus + LM_komplekssus + LM_pikkus_log + sõnajärg + murderühm,
data = dat,
mtry = i)
# ja lisame tapsuste vektorisse iga mudeli klassifitseerimistäpsuse
# see on sama klassifitseerimistäpsus, mida varem table-käsu abil arvutasime
# (i-1 tähendab, et kui i on 2, siis pane täpsus
# vektorisse esimeseks elemendiks, mitte teiseks)
tapsused[i-1] <- sum(diag(mudel$confusion))/sum(mudel$confusion[1:4])
}
tapsused## [1] 0.6835180 0.6675900 0.6537396 0.6523546 0.6537396 0.6544321plot(x = 2:7, y = tapsused,
cex = 1.5,
xlab = "Juhuslike tunnuste arv sõlmes",
ylab = "Mudeli klassifitseerimistäpsus",
main = "Mudeli klassifitseerimistäpsus sõltuvalt sellest,\nkui mitut juhuslikku tunnust igas sõlmes proovitakse")
Näeme, et 2 tunnust igas sõlmes on meie mudeli jaoks tõepoolest optimaalne väärtus, sest rohkematega läheb klassifitseerimistäpsus alla.
Vaatame, kas mudeli täpsus paraneb, kui kasvatame erineval hulgal puid.
# Võtab natuke aega...
tapsused2 <- vector()
puude_arv <- c(10, 100, 500, 1000, 1500, 2000, 3000, 4000)
n <- 1
# Teeme tsükli, kus...
for(i in puude_arv){ # iga arvu i kohta vektoris puude_arv
set.seed(100)
# teeme mudeli, kus kasvatatavate puude arv võrdub i-ga
# (nt mudel, kus ntree = 10; mudel, kus ntree = 100 jne,
# kuni mudelini, kus ntree = 4000)
mudel <- randomForest(cx ~ TR_liik + tegusõna_klass + LM_mobiilsus + LM_komplekssus + LM_pikkus_log + sõnajärg + murderühm,
data = dat,
importance = TRUE,
ntree = i)
tapsused2[n] <- sum(diag(mudel$confusion))/sum(mudel$confusion[1:4])
n <- n+1
}
tapsused2## [1] 0.6675997 0.6869806 0.6855956 0.6862881 0.6876731 0.6918283 0.6918283
## [8] 0.6918283plot(x = puude_arv, y = tapsused2,
cex = 1.5,
xlab = "Kasvatatud puude arv mudelis",
ylab = "Mudeli klassifitseerimistäpsus",
main = "Mudeli klassifitseerimistäpsus sõltuvalt sellest,\nkui mitu puud kasvatatakse")
Näeme, et puude arvu kasvades mudeli klassifitseerimistäpsus paraneb. Küll aga nõuab iga puu kasvatamine ressurssi, mistõttu mingist punktist alates ei ole täpsuse parandamine enam arvutuslikus mõttes mõistlik. Seega nt 2000 ja 4000 puu vahel enam erinevust ei ole. Täpset kriteeriumit puude arvu määramiseks aga paraku ei olegi.
cforest
Tingimuslikud otsustuspuud on tavalistest klassifikatsiooni- ja regressioonipuudest selles mõttes paremad, et need võtavad puudes jagunemiste aluseks p-väärtused ning on sõlmedesse valitud tunnuste valikul vähem kallutatud (vt ka 17. praktikumi materjale).
Tingimuslike otsustuspuude metsa jaoks võib kasutada
partykit-paketi funktsiooni cforest(). See on
uuem ning natuke ressursiahnem kui randomForest(), aga ka
oluliselt täpsem.
cforest-funktsiooni soovitatakse
randomForest-funktsioonile eelistada eriti siis, kui
mudelis on eri tüüpi seletavad tunnused (elimineerib
kallutatuse arvuliste tunnuste ja mitme tasemega kategoriaalsete
tunnuste valikule).
Vaikimisi teeb partykit’i funktsioon
cforest() puid algandmestikust võetud väiksemate juhuslike
valimitega, kus vaatlused ei või korduda (replace = FALSE).
Kui tahta teha mudeleid bootstrap-meetodil, st võtta sama
suured valimid, kus mõned vaatlused võivad korduda, mõned aga jäävad
välja, siis peab täpsustama mudeli funktsioonis parameetri
perturb = list(replace = TRUE).
cforest()-funktsioon on ka party paketis,
ent seal tuleb parameetreid sättida pisut teistmoodi. Vaatame siin
partykit-paketi funktsiooni.
library(partykit)
# Kuna cforest nõuab palju arvutusmahtu, teeme hetkel mudeli 100 puuga.
set.seed(100)
mets_kat_cf <- cforest(cx ~ TR_liik + tegusõna_klass + LM_mobiilsus + LM_komplekssus + LM_pikkus_log + sõnajärg + murderühm,
data = dat,
ntree = 100,
perturb = list(replace = TRUE))# Peame esmalt tegema kõik kategoriaalsed tunnused faktoriteks
kandidaadid[,c("haridus", "sugu", "tähtkuju", "kasutab_meili")] <- lapply(kandidaadid[,c("haridus", "sugu", "tähtkuju", "kasutab_meili")], factor)
set.seed(100)
mets_num_cf <- cforest(log(hääli_kokku) ~ haridus + sugu + tähtkuju + kasutab_meili + nime_pikkus + vanus,
data = kandidaadid,
subset = haridus != "Põhiharidus",
ntree = 100,
perturb = list(replace = TRUE))cforest() kasutab samuti vaikimisi ühes sõlmes
testitavate tunnuste arvuna ruutjuurt kõikide mudelisse kaasatud
seletavate tunnuste arvust (sh ka arvuliste tunnuste puhul), ent ümardab
väärtuse ülespoole.
mets_kat_cf$info$control$mtry # ülespoole ümardatud ruutjuur 6st
## [1] 3
mets_num_cf$info$control$mtry # ülespoole ümardatud ruutjuur 7st
## [1] 3
Mudeli headuse näitajad
Leiame kategoriaalse uuritava tunnusega mudeli
klassifitseerimistäpsuse ja C. Kuna
cforest() ei väljasta ise õigete ja valede ennustuste
risttabelit, tuleb klassifitseerimistäpsuseni jõuda jälle ennustatud
väärtuste ja tegelike väärtuste võrdlemise kaudu.
## enn
## teg ade peal
## ade 530 192
## peal 176 546## [1] 0.7451524## Area under the curve: 0.8237# või
# library(Hmisc)
teg_probs <- ifelse(dat$cx == "peal", 1, 0)
somers2(enn_probs, teg_probs)["C"]## C
## 0.8237276Nagu näha, saame cforest()-funktsiooniga oluliselt
täpsema mudeli ka väiksema arvu puudega. Sellised näitajad saame aga
ilmselt ainult juhul, kui kasutame oma treeningandmeid ühtlasi ka
testandmestikuna. Tegelikult võiksime aga kasutada täpsuse arvutamiseks
OOB-vaatlusi, mida mudel veel näinud ei ole.
# Klassifitseerimistäpsus
teg <- dat$cx
enn <- predict(mets_kat_cf, OOB = T) # OOB = TRUE
t <- table(teg, enn)
sum(diag(t))/sum(t)## [1] 0.6655125# C
# library(pROC)
enn_probs <- predict(mets_kat_cf, type = "prob", OOB = TRUE)[,"peal"]
auc(teg, enn_probs)## Area under the curve: 0.7388# või
# library(Hmisc)
teg_probs <- ifelse(dat$cx == "peal", 1, 0)
somers2(enn_probs, teg_probs)["C"]## C
## 0.738841Saime ikkagi pisut paremad tulemused kui randomForest
funktsiooniga.
Arvuliste uuritavate tunnustega juhumetsadega saab hinnata metsa headust ligikaudselt R2 järgi.
teg <- log(kandidaadid$hääli_kokku[kandidaadid$haridus != "Põhiharidus"])
enn <- predict(mets_num_cf, OOB = TRUE)
(R2 <- cor(enn, teg)^2)## [1] 0.01108888Selle põhjal ei saa aga metsamudelite puhul päriselt öelda, et mudel seletab otseselt 1% uuritava tunnuse varieerumisest. Pigem saab R2 kasutada siin erinevate mudelite võrdlemiseks või ligikaudse mudeli headuse näitajana.
Tunnuste olulisus
Tunnuste olulisust (permutatsiooniolulisust) saab
cforest-objektist kätte funktsiooniga
varimp(). cforest väljastab ainult tunnuste
permutatsiooniolulisuse.
## TR_liik tegusõna_klass LM_mobiilsus LM_komplekssus LM_pikkus_log
## 0.06310928 0.06106395 0.32997251 0.06779852 0.04513624
## sõnajärg murderühm
## 0.01046454 0.08351061# Teeme olulisustest andmetabeli
imps_df <- data.frame(olulisus = imps, # väärtused tulpa "olulisus"
tunnus = names(imps), # tunnuste nimed tulpa "tunnus"
row.names = NULL) # reanimesid pole vaja
head(imps_df)## olulisus tunnus
## 1 0.06310928 TR_liik
## 2 0.06106395 tegusõna_klass
## 3 0.32997251 LM_mobiilsus
## 4 0.06779852 LM_komplekssus
## 5 0.04513624 LM_pikkus_log
## 6 0.01046454 sõnajärg# Teeme joonise
ggplot(data = imps_df,
aes(y = reorder(tunnus, olulisus), x = olulisus)) +
geom_col()
# Või
ggplot(data = imps_df,
aes(y = reorder(tunnus, olulisus),
x = olulisus,
fill = olulisus)) +
geom_point(size = 4, shape = 22, show.legend = FALSE) +
scale_fill_gradient(low = "steelblue4", high = "tomato2") +
labs(x = "",
title = "Tunnuste permutatsiooniolulisus juhumetsa mudelis",
caption = "R-i paketiga partykit (Hothorn & Zeileis 2015)") +
theme_minimal() +
theme(text = element_text(size = 14),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank())
Tavaline permutatsiooniolulisus võib ülehinnata omavahel
seotud/korreleeruvate seletavate tunnuste olulisust. Selle vältimiseks
on partykit-paketis võimalik hinnata tunnuste
tingimuslikku olulisust (conditional
importance, conditional = TRUE). Kuna see on
arvutusmahukas protsess ja võtab omajagu aega, paneme siia ainult koodi
(soovi korral võid enda arvutis läbi jooksutada, aga arvesta selle
andmestiku puhul tavalises sülearvutis vähemalt tunnise ajakuluga).
# Tunnuste tingimuslik olulisus (NB! võib võtta kaua aega)
imps_cond <- varimp(mets_kat_cf, conditional = TRUE)
imps_cond
# Teeme olulisusest andmetabeli
imps_cond_df <- data.frame(olulisus = imps_cond, tunnus = names(imps_cond), row.names = NULL)
head(imps_cond_df)
# Teeme joonise
ggplot(data = imps_cond_df,
aes(y = reorder(tunnus, olulisus), x = olulisus)) +
geom_point(aes(fill = olulisus), size = 4, shape = 22, show.legend = FALSE) +
scale_fill_gradient(low = "steelblue4", high = "tomato2") +
labs(x = "",
title = "Tunnuste tingimuslik permutatsiooniolulisus\njuhumetsa mudelis",
caption = "R-i paketiga partykit") +
theme_minimal() +
theme(text = element_text(size = 14),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank())Kolmas tunnuste olulisuse liik on nn AUC-olulisus,
mis sobib paremini siis, kui
uuritava tunnuse üks väärtus on andmestikus oluliselt sagedasem kui
teine/teised. Selle kasutamiseks on aga puu vaja ehitada mitte
partykit paketiga, vaid hoopis party
paketiga.
#install.packages(c("party", "varImp"))
# desaktiveerime paketi "partykit"
detach("package:partykit", unload = T)
# laadime paketi "party"
library(party)
set.seed(100)
mets_kat_cf_party <- cforest(cx ~ TR_liik + tegusõna_klass + LM_mobiilsus + LM_komplekssus + LM_pikkus_log + sõnajärg + murderühm,
data = dat,
controls = cforest_control(ntree = 100, mtry = 2))
imps_auc <- varImp::varImpAUC(mets_kat_cf_party)
# Teeme olulisusest andmetabeli
imps_auc_df <- data.frame(olulisus = imps_auc, tunnus = names(imps_auc), row.names = NULL)
head(imps_auc_df)## olulisus tunnus
## 1 0.0063928488 TR_liik
## 2 0.0160126690 tegusõna_klass
## 3 0.0799388770 LM_mobiilsus
## 4 0.0169939519 LM_komplekssus
## 5 0.0035859200 LM_pikkus_log
## 6 -0.0006759645 sõnajärg# Teeme joonise
ggplot(data = imps_auc_df,
aes(y = reorder(tunnus, olulisus), x = olulisus)) +
geom_point(aes(fill = olulisus), size = 4, shape = 22, show.legend = FALSE) +
scale_fill_gradient(low = "steelblue4", high = "tomato2") +
labs(x = "", y = "",
title = "Tunnuste AUC-olulisus\njuhumetsa mudelis",
caption = "R-i paketiga party (Hothorn & Zeileis 2006)") +
theme_minimal() +
theme(text = element_text(size = 14),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank())
Juhumetsade visualiseerimine
Üldjuhul kasutatakse juhumetsi kõige olulisemate tunnuste väljaselgitamiseks ning parima mudeli tegemiseks, mida saaks praktikas uute vaatluste klasside/väärtuste ennustamiseks kasutada. Juhumets on oma olemuselt nn musta kasti mudel ega võimalda vaadata metsa sisse samamoodi nagu üksikute puude puhul. Seega ei näe me, mil moel täpselt mingid tunnused uuritava tunnuse väärtust mõjutavad.
On siiski mõned visualiseerimistehnikad, mis võimaldavad seletavate tunnuste üldmõjusid ja interaktsioone visualiseerida sarnaselt regressioonimudelitega. Üheks selliseks tehnikaks on nn osalise sõltuvuse graafikud (partial dependence plots), mis visualiseerivad korraga ühe seletava tunnuse (või tunnustevahelise interaktsiooni) mõju uuritavale tunnusele. Põhimõtteliselt on tegemist sama asjaga, mida nägime regressioonimudelite juures marginal effects nime all, kus mudeli abil ennustatakse mingites tüüpkontekstides iga seletava tunnuse väärtusest sõltuvalt mingit sündmuse toimumise tõenäosust.
Vaatame funktsiooni plotmo() võimalusi
samanimelises paketis.
Selle kõige lihtsamas versioonis hoitakse ühe seletava tunnuse mõju
hindamisel teiste arvuliste seletavate tunnuste väärtused nende
mediaani peal ning kategoriaalsete tunnuste väärtused
nende kõige sagedamal/tüüpilisemal tasemel (= moodi peal).
Määrates funktsioonis argumendi trace = 1, näitab
funktsioon ka seda, millised need väärtused täpsemalt on. Neid väärtusi
saab muuta funktsioonis argumentidega grid.func ja
grid.levels (vt lähemalt paketi dokumentatsioonist).
plotmo paketi tegijad ise nimetavad seda ka “vaese mehe
osalise sõltuvuse graafikuks”. See on kiirem ning annab enam-vähem
ülevaate tunnustevahelistest sõltuvussuhetest.
## variable importance: TR_liik tegusõna_klass LM_mobiilsus LM_komplekssus LM_pikkus_log sõnajärg murderühm
## stats::predict(cforest.object, data.frame[3,7], type="response")
## stats::fitted(object=cforest.object)
## got model response from model.frame(cx ~ TR_liik + tegusõna_klass + LM_mo...,
## data=object$data, na.action="na.fail")##
## plotmo grid: TR_liik tegusõna_klass LM_mobiilsus LM_komplekssus
## nimisõnafraas olemisverb staatiline lihtsõna
## LM_pikkus_log sõnajärg murderühm
## 1 tr_lm Kesk
Vaikimisi teeb plotmo graafiku, mis ennustab uuritava
tunnuse klasse (type = "response"). Seega
tähendab “1” meie andmestiku puhul seda, et kasutatakse
ade-konstruktsiooni, ning “2” seda, et kasutatakse
peal-konstruktsiooni (juhul, kui hoida kõik teised tunnused
kindlal tasemel!).
Näiteks kontekstis, kus tegusõna_klass = "olemisverb",
LM_mobiilsus = "staatiline",
LM_komplekssus = "lihtsõna",
LM_pikkus_log = 1, sõnajärg = "tr_lm" ja
murderühm = "Kesk", kasutatakse pigem
peal-konstruktsiooni, kui TR_liik = "asesõna" või
TR_liik = "nimisõnafraas", ja pigem
ade-konstruktsiooni, kui TR_liik = "verbifraas"
(joonis “1 TR_liik”).
Kontekstis, kus TR_liik = "nimisõnafraas",
LM_mobiilsus = "staatiline",
LM_komplekssus = "lihtsõna",
LM_pikkus_log = 1, sõnajärg = "tr_lm" ja
murderühm = "Kesk", kasutataks
peal-konstruktsiooni pigem siis, kui tegusõna on olemis- või
tegevusverb või kui tegusõna pole (joonis “2
tgsn_klss”) jne. Selles mõttes sarnaneb nende graafikute
tõlgendamine paljuski regressioonimudelite tõlgendamisega.
Lisaks üksikute tunnuste mõjude kuvamisele näitab plotmo
3D-graafikul ka olulisemate interaktsioonide mõju uuritavale tunnusele
(kui tahta kuvada kõiki võimalikke interaktsioone, siis saab täpsustada
plotmo() funktsioonis all2 = TRUE).
Nii näiteks näeb, et ehkki nii liigutatavate kui ka staatiliste
kohasõnade referentidega ennustatakse (teiste tunnuste fikseeritud
kontekstis) pigem peal-konstruktsioone (joonis “3
LM_moblss”), siis olukorras, kus trajektori liik on verbifraas
ja tegemist on staatilisele kohale viitava orientiiriga, ennustatakse
siiski ade-konstruktsiooni (joonis “2 TR_liik:
LM_moblss”). Nooled näitavad, mispidi tunnuse väärtused
graafikul muutuvad: arvuliste tunnuste puhul suunab nool väiksemast
väärtusest suuremani ning kategoriaalsete tunnuste puhul tähestiku
järjekorras esimesest tasemest tagumiseni.
Ilmselt oleks aga informatiivsem vaadata graafikuid mitte ennustatud
klasside, vaid tõenäosuste põhjal, kuna see võimaldab
paindlikumat analüüsi. Selleks lisame funktsiooni argumendi
type = "prob".
## variable importance: TR_liik tegusõna_klass LM_mobiilsus LM_komplekssus LM_pikkus_log sõnajärg murderühm
## stats::predict(cforest.object, data.frame[3,7], type="prob")
## stats::fitted(object=cforest.object)
## set nresponse=2
## nresponse=2 but for plotmo_y using nresponse=1 because ncol(y) == 1
## got model response from model.frame(cx ~ TR_liik + tegusõna_klass + LM_mo...,
## data=object$data, na.action="na.fail")##
## plotmo grid: TR_liik tegusõna_klass LM_mobiilsus LM_komplekssus
## nimisõnafraas olemisverb staatiline lihtsõna
## LM_pikkus_log sõnajärg murderühm
## 1 tr_lm Kesk
Näeme, et tõenäosustena esitatuna ei ole erinevused ade ja peal-konstruktsioonide kasutamises üldse nii suured kui kategoorilises esituses.
Kui tahaksime kuvada interaktsioone 3D-graafikute asemel näiteks
toonide kaudu, võime kasutada funktsioonis lisaks argumenti
type2 = "image", kus tumedamad toonid näitavad väiksemat
tõenäosust ning heledamad suuremat.
## variable importance: TR_liik tegusõna_klass LM_mobiilsus LM_komplekssus LM_pikkus_log sõnajärg murderühm
## stats::predict(cforest.object, data.frame[3,7], type="prob")
## stats::fitted(object=cforest.object)
## set nresponse=2
## nresponse=2 but for plotmo_y using nresponse=1 because ncol(y) == 1
## got model response from model.frame(cx ~ TR_liik + tegusõna_klass + LM_mo...,
## data=object$data, na.action="na.fail")##
## plotmo grid: TR_liik tegusõna_klass LM_mobiilsus LM_komplekssus
## nimisõnafraas olemisverb staatiline lihtsõna
## LM_pikkus_log sõnajärg murderühm
## 1 tr_lm Kesk
Võime valida ka ainult kindlad graafikud, mida näha tahame. Peamõjude
valimiseks saab kasutada argumenti degree1 ning
interaktsioonide jaoks argumenti degree2.
plotmo(object = mets_kat_cf,
trace = 1,
type = "prob",
type2 = "image",
degree1 = c("TR_liik", "LM_mobiilsus"),
degree2 = c("TR_liik", "LM_mobiilsus"))plotmo-paketiga saab teha ka n-ö päris osalise sõltuvuse
graafikuid, kus iga konkreetse seletava tunnuse juures kõikide teiste
seletavate tunnuste tasemete mõju keskmistatakse selle asemel, et
määrata lihtsalt läbivalt mingi fikseeritud taustakontekst. Need
graafikud annavad seega pisut adekvaatsema pildi üksikute seletavate
tunnuste marginaalsest mõjust, kuna ei arvesta ainult mingit üht
spetsiifilist konteksti. Osalise sõltuvuse graafikute jaoks määrame
argumendi pmethod väärtuseks partdep. Kuna
tunnuseid on mitu ning meetod komplekssem ja arvutusmahukam, läheb
sellise graafiku tegemiseks ka rohkem aega. Kuvame siin seega ressursi
kokkuhoiu mõttes ainult peamõjud ning jätame interaktsioonid kuvamata
(degree2 = FALSE).
Üldjoontes näeme samasuguseid trende nagu regressioonimudelis: trajektori liigil, kohafraasi pikkusel ja sõnajärjel ei ole olulist seost ade- ja peal-konstruktsioonide valikuga. peal-konstruktsiooni tõenäosus on suurem koos liigutatavatele kohtadele viitavate sõnadega (laua peal), lihtsõnadega, tegusõnadega, mis ei viita liikumisele. Samuti on Kesk- ja Lõuna-murderühmad oluliselt peal-konstruktsiooni lembesemad kui Ranniku- ja Saarte-murderühma murded.
Osalise sõltuvuse graafikute tegemiseks on ka teisi pakette, nt
pdp, ICEbox ja edarf. Ka
randomForest-paketil on tegelikult sisseehitatud
partialPlot() funktsioon, ent sellega saab korraga kuvada
ainult üht tunnust ning y-teljel ei ole kuvatud mitte tõnäosused, vaid
tunnuse väärtuste suhteline mõju uuritavale tunnusele (negatiivsel
poolel “peal” esinemisele, positiivsel poolel “ade” esinemisele).
par(mfrow = c(4,2))
randomForest::partialPlot(mets_kat_rf, x.var = "TR_liik", pred.data = dat)
randomForest::partialPlot(mets_kat_rf, x.var = "tegusõna_klass", pred.data = dat)
randomForest::partialPlot(mets_kat_rf, x.var = "LM_mobiilsus", pred.data = dat)
randomForest::partialPlot(mets_kat_rf, x.var = "LM_komplekssus", pred.data = dat)
randomForest::partialPlot(mets_kat_rf, x.var = "LM_pikkus_log", pred.data = dat)
randomForest::partialPlot(mets_kat_rf, x.var = "sõnajärg", pred.data = dat)
randomForest::partialPlot(mets_kat_rf, x.var = "murderühm", pred.data = dat)
Kordamisküsimused
1. Milline väide on õige?
- R-ruut on täpne arvulise uuritava tunnusega puu- ja metsamudelite headuse näitaja.
- Seletavate tunnuste permutatsiooniolulisus on täpsem näitaja kui Gini-indeksil põhinev olulisus.
- Z-skoorid on tundlikud valimi suuruse ja puude arvu suhtes.
- Metsamudelite tunnuste olulisust saab visualiseerida osalise sõltuvuse graafikutel.
2. Milles seisneb juhumetsa juhuslikkus?
- Mudeli ennustused üldistatakse mitme puumudeli põhjalt, mis omakorda on treenitud algandmestikust juhuslikult võetud valimitel.
- Iga puu igas sõlmes tehakse vaatluste jagamiseks valik juhuslikult valitud seletavate tunnuste hulgast.
- Mudelis kasvatatavates puudes ennustatakse lehtedesse juhuslikke uuritava tunnuse väärtuseid.
- Seletavad tunnused, mida metsamudelisse kaasatakse, on valitud kõikidest andmestikus olevatest tunnustest juhuslikult.
3. Mis on out-of-bag-vaatlused?
- Metsamudeli poolt tegelikele vaatlustele ennustatud väärtused.
- Algandmestiku vaatlused, millel mudeleid treenitakse.
- Algandmestiku vaatlused, mis jäävad metsamudelis iga üksiku puu kasvatamiseks võetud juhuvalimist välja.
Funktsioonide sõnastik
importance()- küsi tunnuste olulisusi randomForesti paketiga
plotmo::plotmo()- visualiseeri tunnuste mõjusid juhumetsa mudelis
randomForest::partialPlot()- visualiseeri tunnuste mõjusid randomForesti juhumetsa mudelis
randomForest::randomForest()- tee juhumets randomForesti paketiga
partykit::cforest()- tee tingimuslik juhumets partykiti paketiga
varimp()- küsi tunnuste olulisusi partykiti paketiga
varImp::varImpAUC()- küsi tunnuste AUC-olulisusi
varImpPlot()- tee tunnuste olulisuse graafik randomForesti paketiga